Elixir and Kubernetes (for your developers)
How to deploy Elixir on Kubernetes for your curious developers.


What's Kubernetes?
Following the official Kubernetes website (on the 30th november in 2022):
Kubernetes also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications.
So, on our dev point of view, this is a tool that will let us automatically deploy containers, handle and configure them, but also to scale them.
We're going first to see mostly those following principles in this post:
- secrets
- config maps
- deployments
- services
And then we're going to tackle some "bonuses", aka:
- Elixir/Erlang clusters inside a kubernetes cluster
- PostgreSQL persistence (as first we're going to have our data wiped if we destroy our PostgreSQL deployment)
- Ingress (in another post because I've still have to "write" it)
Why Kubernetes?
Why Kubernetes, for an Elixir application you ask? Well, first because our infrastructure (testing, preprod and prod), and also our CI/CD pipelines were in a sad state.
So, when management thought about going on Kubernetes, it was not a shocking idea.
We also have NodeJS and React (and we would be getting Python later down) applications, so a not-only-BeamVM solution sounds good.
Also, were we using hot-code reloading? Or even ready to use it? Not at all. You can follow along more about that logic in the very good Dashbit post about K8S and Elixir: https://dashbit.co/blog/kubernetes-and-the-erlang-vm-orchestration-on-the-large-and-the-small.
Anyway, the DevOps team and the CTO at that time felt Kubernetes was a sensible option, and to this day I agree with it.
That company operated at some scale and had certains needs of SLA and resilience and deployment.
We developed a lot of in-house tools around our not-using kubernetes that were already present in kubernetes, with, often, a higher quality. Of course, we also had to maintain and configure our own in-house tooling.
And I think, mostly for that, it was a reasonable option.
But I did not learn Kubernetes for that project or that company: I just wanted to learn Kubernetes :D.
That's actually the reason I began learning it. I wanted to know more and see what it was about and how it was working.
I was also seeing the state of the job market, and knew that I was planning to move to Québec, and I needed more for my CV (and it's still not enough sadly).
The company project to move to Kubernetes was totally disconnected and came a few months later (and I did not participate in choosing the technology or planning the AWS side of it).
I got assigned to it not even because of my k8s learning, but because I was at ease with Github Actions and Docker, and complaining about our slow and flanky pipeline and the deprecated versions we were using and how our infrastructure prevented us from using newer versions in any proof of concept or product, with my experience and knowledge and a plan on how to do better to back my complaining.
Again, more in my first blog post about our actual migration (and how it actually did not involve Kubernetes, here: https://blog.adrianc.eu/post-mortem-of-a-platform-engineering-tentative/
Anyway, let's get back to our learning and blogging.
Our application
We're going to deploy an Elixir web application, which will connect to a PostgreSQL database.
So, for that, we will need to create the database with a Deployment, to configure with Secrets and ConfigMaps, and then expose it in the cluster through a Service.
Likewise with the web app, we will need a Deployment, a Secret and the Service.
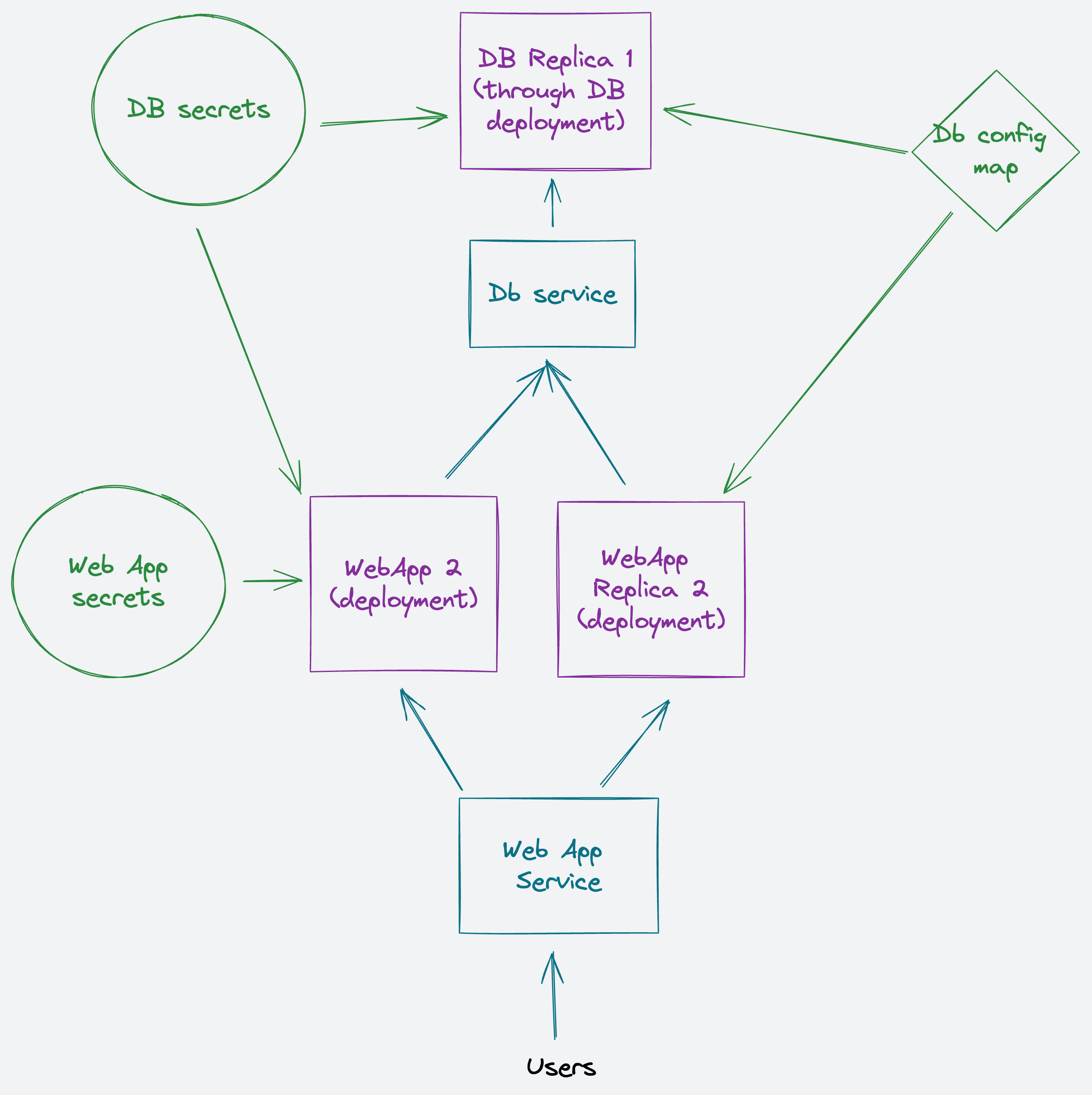
We will be using the kubectl apply -f command on each file (or in a folder).
PostgreSQL
Secrets
Secrets are basically environment variables that are sensible, like tokens or passwords.
To avoid writing them in clear in the application, where they could be accessed while we view, create or edit a Kubernetes Pod, we will use a Secret.
Be aware that here we're going to use the basic Kubernetes secrets, where values are only base64 encoded. If you want to use a more robust solution, for a real production environment, I would recommend taking a look at stuff like Vault from Hashicorp, or even 1Password.
Here, we're going to only put the login credentials of the database in the secrets.
apiVersion: v1
kind: Secret
metadata:
name: postgres-secret
type: Opaque
data:
POSTGRES_USER: cG9zdGdyZXNxbA==
POSTGRES_PASSWORD: dG9wc2VjdXJlConfigMap
The ConfigMap is a simple key-value system to handle environment variables in our case. We're going to configure the host, the port and database name to configure PostgreSQL.
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-configmap
data:
POSTGRES_HOST: postgres-service
POSTGRES_DBNAME: api
PG_PORT: "5432"
POSTGRES_DB: apiDeployment
Deployments define in which state you want your pods (your containers) and their replicas. We can configure the container directly, but also add metadata onto it, change (and so upgrade) the image to use, scale up or down the number of replicas.
I'm going to divide the file in multiple part for ease of reading, but I will share the full file later.
First, we will get our metadata straight, there only the label app=postgres
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
labels:
app: postgresNow it's ReplicaSet time. In our case we only want one replica on everything that matches the app=postgres label we configured earlier.
spec:
replicas: 1
selector:
matchLabels:
app: postgresThen we can define our pods, still with the metadata, and then the containers, with their image, ports, everything:
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:latest
ports:
- containerPort: 80Finally we can configure our environment variables. In our case we're going to reference the ConfigMaps and Secrets we configured earlier.
envFrom:
- configMapRef:
name: postgres-configmap
- secretRef:
name: postgres-secretThe full file:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
labels:
app: postgres
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:latest
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: postgres-configmap
- secretRef:
name: postgres-secretService
Services let us expose an application on one or more kind of Pods.
Each Pod has it own ("cluster-internal") IP, but each Pod being "temporary" (read more or less temporary, you could have a Pod that live for months and other that changes every hour, for instance with CI/CD!), we can't really use that specific IP to connect Pods with each other.
That's why we're going to use Services, that gives a unique DNS name for a set of Pods, and which can also act as a load balancer between those Pods.
We're going to use a selector on the app=postgres label, to choose to expose the pods that are postgreSQL related.Then we have to choose the type of Service. In our case, we only want an _internal_ access of PostgreSQL. We don't want to access PostgreSQL from outside our k8s cluster. So we're going to choose the ClusterIP type.
We're going to use the TCP protocol, and open and listen on the 5432 port (so we're going to talk to that port but also we're going to knock on the 5432 port of our Pods).
apiVersion: v1
kind: Service
metadata:
name: postgres-service
spec:
selector:
app: postgres
type: ClusterIP
ports:
- protocol: TCP
port: 5432
targetPort: 5432Elixir
It's Elixir time!We're going to use this application: https://github.com/AdrianPaulCarrieres/kubix
Dockerfile
We have to put our application in a container first. So here is our Dockerfile. It's mostly the same you would get by autogenerating it with the mix task.
ARG ELIXIR_VERSION=1.14.2
ARG OTP_VERSION=25.1.2
ARG DEBIAN_VERSION=bullseye-20221004-slim
ARG BUILDER_IMAGE="hexpm/elixir:${ELIXIR_VERSION}-erlang-${OTP_VERSION}-debian-${DEBIAN_VERSION}"
ARG RUNNER_IMAGE="debian:${DEBIAN_VERSION}"
# Multistage build
FROM ${BUILDER_IMAGE} as builder
# install build dependencies
RUN apt-get update -y && apt-get install -y build-essential git \
&& apt-get clean && rm -f /var/lib/apt/lists/*_*
# prepare build dir
WORKDIR /app
# install hex + rebar
RUN mix local.hex --force && \
mix local.rebar --force
# set build ENV
ENV MIX_ENV="prod"
# install mix dependencies
COPY mix.exs mix.lock ./
RUN mix deps.get --only $MIX_ENV
RUN mkdir config
# copy compile-time config files before we compile dependencies
# to ensure any relevant config change will trigger the dependencies
# to be re-compiled.
COPY config/config.exs config/${MIX_ENV}.exs config/
RUN mix deps.compile
# Copy assets, migrations file
COPY priv priv
# Source code
COPY lib lib
COPY assets assets
# compile assets
RUN mix assets.deploy
# Compile the release
RUN mix compile
# Changes to config/runtime.exs don't require recompiling the code
COPY config/runtime.exs config/
COPY rel rel
RUN mix release
# start a new build stage so that the final image will only contain
# the compiled release and other runtime necessities
FROM ${RUNNER_IMAGE}
RUN apt-get update -y && apt-get install -y libstdc++6 openssl libncurses5 locales postgresql-client \
&& apt-get clean && rm -f /var/lib/apt/lists/*_*
# Set the locale
RUN sed -i '/en_US.UTF-8/s/^# //g' /etc/locale.gen && locale-gen
ENV LANG en_US.UTF-8
ENV LANGUAGE en_US:en
ENV LC_ALL en_US.UTF-8
WORKDIR "/app"
COPY entrypoint.sh .
RUN chown nobody /app
# set runner ENV
ENV MIX_ENV="prod"
# Only copy the final release from the build stage
COPY --from=builder --chown=nobody:root /app/_build/${MIX_ENV}/rel/kubix ./
USER nobody
CMD ["bash", "./entrypoint.sh"]Then we're going to need a little bash script to wait for the database and then start the migrations.
To be noted that we could also use a special deployment to run our migrations too.
It can be useful because some migrations can take a super long time, and our application wouldn't be up for dozen of minutes, whereas the default k8s behavior is to shutdown every deployment that doesn't go online after a mere minutes if not seconds.
So you could have a normal deployment with a low timeout to rollback, for your normal application, and then another that can wait a migration-long-amount-of-time.
#!/bin/bash
# docker entrypoint script.
# assign a default for the database_user
DB_USER=${DATABASE_USER:-postgres}
while ! pg_isready -h $POSTGRES_HOST -U $POSTGRES_USER
do
echo "$(date) - waiting for database to start"
sleep 2
done
bin="/app/bin/"
/app/bin/migrate
/app/bin/serverWe're also going to have a .dockerignore to remove "useless" or sensible files that we don't want to copy inside our container when building it. It can lead to a better security, but more importantly reduce the size of the image (or % of luck of busting your cache while building it).
.dockerignore
# Ignore git, but keep git HEAD and refs to access current commit hash if needed:
#
# $ cat .git/HEAD | awk '{print ".git/"$2}' | xargs cat
# d0b8727759e1e0e7aa3d41707d12376e373d5ecc
.git
!.git/HEAD
!.git/refs
# Common development/test artifacts
/cover/
/doc/
/test/
/tmp/
.elixir_ls
# Mix artifacts
/_build/
/deps/
*.ez
# Generated on crash by the VM
erl_crash.dump
# Static artifacts - These should be fetched and built inside the Docker image
/assets/node_modules/
/priv/static/assets/
/priv/static/cache_manifest.json
/k8sSecret
Phoenix also needs a secret to work, the secret key base.
apiVersion: v1
kind: Secret
metadata:
name: elixir-secret
type: Opaque
data:
SECRET_KEY_BASE: clhDN2lQNGd3dWttTlpYS0FhWmZvc1VVWGxyOFBCa2VRRkFkcXhoWWdSK0thNjlPY3g3cG9Pa1A1UUFJMlI1dA==ConfigMap
We're basically going to add a HOST and an environment variable to tell Phoenix to start with its web server:
apiVersion: v1
kind: ConfigMap
metadata:
name: elixir-configmap
data:
PHX_HOST: localhost
PHX_SERVER: "true"Deployment
First we need our metadatas:
apiVersion: apps/v1
kind: Deployment
metadata:
name: elixir
namespace: default
labels:
app: kubix
tier: webThis time we want at least two replicas for our deployment:
spec:
replicas: 2
selector:
matchLabels:
app: kubixThen it's container configuration time:
spec:
containers:
- name: kubix
image: docker.io/adrianpaulcarrieres/kubix2:1.1
imagePullPolicy: Always
ports:
- containerPort: 443Then we're going to pass down multiple environment variables:
- PostgreSQL's Secret, to log in the database
- PostgreSQL's ConfigMap, to know where to knock to
- Elixir's Secret
- Some metadatas from the k8s cluster, to do our Elixir/Erlang clustering dark magic (yeah I know it's one of the bonuses)
envFrom:
- secretRef:
name: elixir-secret
- configMapRef:
name: postgres-configmap
- secretRef:
name: postgres-secret
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIPThe full file:
apiVersion: apps/v1
kind: Deployment
metadata:
name: elixir
namespace: default
labels:
app: kubix
tier: web
spec:
replicas: 2
selector:
matchLabels:
app: kubix
template:
metadata:
labels:
app: kubix
tier: web
spec:
containers:
- name: kubix
image: docker.io/adrianpaulcarrieres/kubix2:1.1
imagePullPolicy: Always
ports:
- containerPort: 443
envFrom:
- secretRef:
name: elixir-secret
- configMapRef:
name: postgres-configmap
- secretRef:
name: postgres-secret
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIPService
Service time! We want to be able to talk to our application from outside the k8s cluster, so we're going to use another Service, the LoadBalancer.
That's also when you should think about the Ingress stuff, but that will be for another time (maybe).
apiVersion: v1
kind: Service
metadata:
name: kubix-service
spec:
selector:
app: kubix
type: LoadBalancer
ports:
- protocol: TCP
port: 4000
targetPort: 4000
nodePort: 30000Visiting the web app
So to get to our web app, we can either get the IP from the k8s dashboard, or from the command kubectl get services.
From the dashboard, we can click on the "terminaison externe" (or something else in English) for our kubix-service.
In my screenshot, the port for my service is 30 001 because I locked myself out of the 30 000 one by accident while creating the Service!
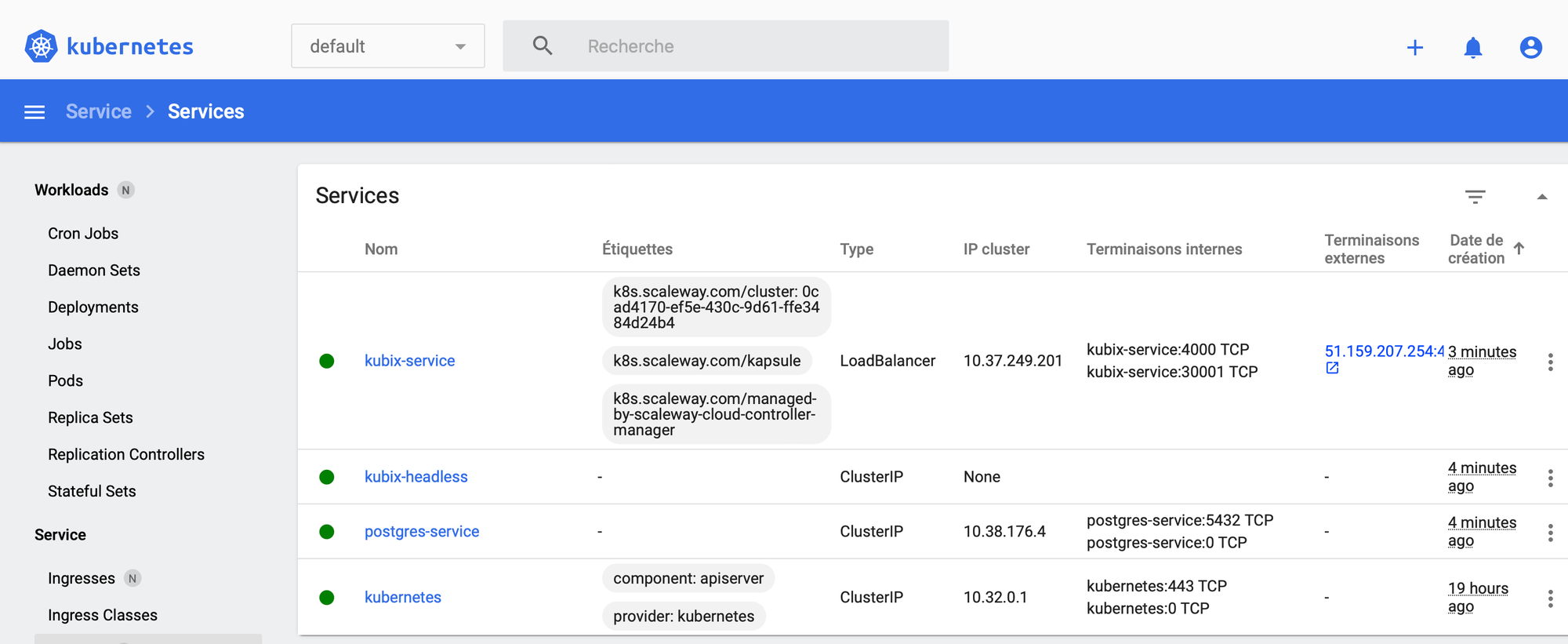

k get services where we can see a kubix-service, of type LoadBalancer, internal terminaisons and external onesBonuses time!
We're going to:
1. Create our Elixir cluster inside the k8s cluster
2. Fix some issue with websockets for Phoenix LiveView
3. Handle PostgreSQL persistence. Right now, if you delete your Pod, it's bye bye. We don't want that usually
4. (In the future but) use Ingress.
Clusters inside Clusters
We've already done some work by adding our Kubernetes metadata inside our Deployment earlier (yes, that was a bad tutorial move, sorry).
Elixir changes
We're going to change some stuff inside rel/env.sh.eex
We need to tell Elixir to start as a node named @release.name %>@${POD_IP} (yeah that's not an easy name to bear I know). It will mostly tell Elixir to use our POD_IP environment variable to start.
Then we're going to add libcluster to do our actual clustering work. I will let you figure out how to install it, but as for the configuration we mostly have to add our cluster supervisor to our supervision tree in lib/kubix/application.ex
{Cluster.Supervisor, [topologies, [name: Kubix.ClusterSupervisor]]}
and then we have to configure the topologies:
config :libcluster,
topologies: [
k8s_example: [
strategy: Elixir.Cluster.Strategy.Kubernetes.DNS,
config: [
service: "kubix-headless",
application_name: "kubix"
]
]
]It will tell libcluster to use a DNS name, kubix-headless, to find the different Pods to connect to.
And we're now going to create and configure this kubix-headless thing, which is a (special) Service, if you have followed along.
Headless Service
A Headless Service is basically a Service used when we don't need to do LoadBalancing, or even don't use an IP address.
Here we're only going to use it to group Pods together and to let them _discover_ and connect together.
It's basically an _internal_ DNS name that every Pod will know.
We still want this Service to "select" our kubix applications (the same label as our Deployment). It's a ClusterIP, so internal, but without a port or an IP:
apiVersion: v1
kind: Service
metadata:
name: kubix-headless
spec:
selector:
app: kubix
type: ClusterIP
clusterIP: NoneLiveView and the WebSocket problem
So, I had actually done the "PostgreSQL" bonus before this one, and when I wanted to test it through LiveView, I saw that the websocket wasn't working properly, because of a host issue.
Supposedly, because it works but I'm not sure of the security implication of it, we only need to configure our Endpoint with the last line:
config :kubix, KubixWeb.Endpoint,
url: [host: host, port: 4000, scheme: "https"],
http: [
ip: {0, 0, 0, 0, 0, 0, 0, 0},
port: port
],
secret_key_base: secret_key_base,
check_origin: :connIt's telling Phoenix to allow any origin matching the request connection's host, port, and scheme, but still, I'm not exactly sure what it actually means in our k8s context. To be explored later!
PostgreSQL data persistence
We're going to add a volume in the ConfigMap for PostgreSQL:
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-configmap
data:
POSTGRES_HOST: postgres-db-service
POSTGRES_DBNAME: api
PG_PORT: "5432"
POSTGRES_DB: api
PGDATA: /var/lib/postgresql/data/pgdataThen we're going to change our PostgreSQL Deployment, to use a StatefulSet instead.
A StateFulSet is a bit like a Deployment, because it's going to use the same spec for multiple containers.
The biggest difference comes from the fact that each Pod will be identified in a unique way, and every Pod will be created or deleted in the same order. It can be useful to handle our volume for our database.
While debugging this, I've changed the name of the service and the application, but you mostly needs to add this for the container:
volumeMounts:
- name: postgres-db-volume
mountPath: /var/lib/postgresql/dataand then for the StateFulSet:
volumeClaimTemplates:
- metadata:
name: postgres-db-volume
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1GiThe full file, as usual:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres-db
spec:
selector:
matchLabels:
app: postgres-db
serviceName: postgres-db-service
replicas: 1
template:
metadata:
labels:
app: postgres-db
spec:
containers:
- name: postgres-db
image: postgres
envFrom:
- configMapRef:
name: postgres-configmap
- secretRef:
name: postgres-secret
volumeMounts:
- name: postgres-db-volume
mountPath: /var/lib/postgresql/data
volumeClaimTemplates:
- metadata:
name: postgres-db-volume
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1GiSmall update inside postgreSQL's Service to respect the same name:
apiVersion: v1
kind: Service
metadata:
name: postgres-db-service
spec:
selector:
app: postgres-db
type: ClusterIP
ports:
- protocol: TCP
port: 5432
targetPort: 5432You might need to wait a little to start your StatefulSet, but otherwise you should be good!
Ingress
Sadly I never got to play with Ingress, and right now (as of 2025/01/06) I still have to find an income and can't really spare the money to get a handful of Kubernetes nodes to play with. But!
The basic idea of Ingress is to handle the way requests are coming from outside of the cluster into the cluster. So you will for instance use nginx to configure that kind of things, and allow/disallow routes and such. Maybe I will be able to try it and write about it soon :)
Other K8S stuff I haven't played with
Wellll, mostly helm charts. I did try my hands using them but I have not written one myself. Which kinda would be the next step after the Ingress thingy. Maybe soon, too?
Basically it's another... more compact/linked? way of writing every file we wrote in that blog post. You deploy a stack directly, instead of its elements one by one, as I understand it.